Ok, first thing first, forget about the terminologies used in VSS. Those terminologies are never used in SVN except for
SVN Check out which is a bit different from the
VSS CheckOut. We will explain this in detail later.
Installing an SVN Client:
Please install the tortoise SVN client from
http://download.cnet.com/TortoiseSVN-64-bit/3000-2383_4-75211577.html (64 bit)
http://download.cnet.com/TortoiseSVN-32-bit/3000-2383_4-10800080.html (32 bit)
OR directly from the Tortoise SVN Site.
http://tortoisesvn.net/downloads.html
Once the installation is complete, right click anywhere and you will have a right click option window like below.
You can see the options like “
SVN Checkout” and “TortoiseSVN -->”. Hold your horses, we will explain these in detail later.
If you do not find these options in the right click, then the installer package is probably not supported by your OS. You need to either install an older version or a newer version based on the type of OS and Service Pack you have.
SVN Checkout, Downloading the Source Code for the first time:
Yes, we use SVN Checkout only once for downloading the source code for the first time.
After we have downloaded the source code for the first time, we then use
SVN Update and
SVN Commit (
Patience: will be explained later) for updating/committing your local code from/to the code repository.
How the SVN Checkout works? Well we need a project directory, lets say,
Project_SVN on Desktop. We will navigate to
Project_SVN directory. Inside that we will right click and then we will click on the
SVN Checkout and a window like the following will appear.
Enter the repository url given to you by SVN adminstrator in the
URL of repository as shown above. Click
OK and it will ask for the authentication as below
Enter your username and password. If you want, you can “
Save authentication” so that you may not enter the authentication each time you access the repository.
Once the authentication process is complete, it will start downloading the code. When the download finishes, it will enable the OK button at the bottom.
After the checkout finishes, you will see a folder structure like below
The green signs on folders and files mean that your local code has no changes since the last update.
Now, right click in the
Project_SVN folder and you will see additional SVN commands as below.
SVN Update:
When someone else does some changes in a file and commits it to the code repository, you will never know of it. That’s a pitfall to SVN (
really? I don’t think so). SVN works in an offline mode and that’s why it perfectly suits faster development. So if I don’t know which file is worked by whom, and I really don’t care in an offline mode as SVN works in an offline mode, then how will I know that I need to get the latest code. Well for that we will follow the following 2 golden rules.
1. You
SHOULD always update your code at the beginning of the day.
2. You
MUST always update your code before committing your changes because it is possible that the file you have worked on may have been changed by someone else in your team at the repository. So when you update, his/her code will be merged to your changed file. And after that you will commit your changes, fair enough, isn’t it?
So how do we do an SVN Update? Just right click in a folder you want to update and click the
SVN Update. It will ask for authentication if you haven’t saved it already.
SVN Commit:
Remember; always do an SVN Update before an SVN Commit.
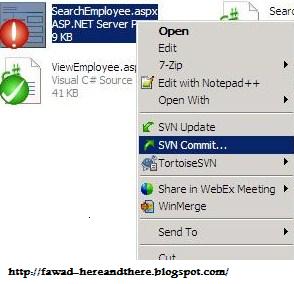
So how do we know that we need to commit? Simple, if you have
red files in your LOCAL repository, you need to do an SVN Commit and if your functionality, you are working on, is complete.
In this figure, we can see that some changes have been made to hr and nomination folder.
How do we do SVN Commit? There are 2 ways of doing it.
1. We need to reach out for each red file in the hierarchy and right click on it and then click the svn commit.
2. Right Click at the root of the local directory and click on SVN Commit. A window will appear containinig a list of all locally changed files. You can select/deselect from that list of files and click OK at the bottom.
The above figure shows that 2 files have been changed at the local code repository. You can add a comment for the commit as well.
SVN DIFF:
What if we want to know what changes have we made locally. Local changes mean that the file will be in
red. So navigate to that file. Right Click on it, hover on “
TortoiseSVN -->” and click on
Diff.
After clicking
Diff, a window like below will open.
The left side shows code at the repository. The right side shows code on your local. The Orange and yellow line indicates that this line contain changes, in this case an extra space has been added.
SVN Show log:
This is used to check the log history as who committed what and when. This can be triggered through the following figure.
And the log history is shown like below.
One portion of the window shows the names of the people who committed the code. When we click on a name, we see which files he/she committed in the bottom section. If we click on a file in the bottom section, it will open an
SVN Diff window showing a comparison between the code committed in that version and a previous version. We can also see revision Numbers in the log history. These versions will be used in
SVN Update to revision.
SVN Update to revision:
If we want to revert a file to a previous version in time, we can do that by
SVN Update to revision. We can do it as shown in the following figure.
Clicking it will appear another window as shown
Type in the revision number and click Ok.
Adding Files To Repository:
If we want to place new files to the SVN repository, we can do it by SVN Add. If we add a non-versioned file to the SVN local folder, it will look like below.
The question mark shows that this file is not versioned yet. Right click on the image and follow the figure below.
Click on the
Add… option and the file will be versioned. Now you need to right click on the image and commit it.
Resolving Conflicts:
By now, you know that while working with SVN, UNLIKE VSS, you do not know if a file you are working on has been changed by someone else on the repository. SVN takes the burden of merging such changes. But SVN fails at one point when the changes being made are at the same line, by same line I mean same line number. In this case when you do an update, svn shows that some files are in conflict. SVN generates 4 copies of the same file in this case. Lets assume that the other guy’s name is Mr. X who made changes to the same file on the same lines I worked on
1. Merged File. Contains changes from both me and Mr. X.
2. My file. Contains my changes. It does not have changes from Mr. X.
3. Current Version file. This is the file which Mr. X committed to repository. It does not contain my changes
4. Previous Version. It neither contains changes from me nor from Mr. X.
If we ever came across any conflicts, we will use these files to resolve the issue.
Thats all from me.Hope this article will help someone out there.